Всем привет! Недавно изучая статистику задумался об идее а какие факторы влияют на выступление на Олимпиадах. На это у меня было бесчисленное количество бесед с другими олимпиадниками, но они всегда ограничивались логическими доводами и персональными наблюдениями. Что ж, я предлагаю прочесть небольшой пост насчет более численного метода. Буду рад услышать ваши мысли.
Вступление
В последние годы в олимпиадной химии в Казахстане распространенной практикой является отбор участников на Менделеевскую олимпиаду, использую результаты Республиканского этапа. Во многих случаях причиной была нехватка времени для проведения дополнительных сборов, по результатам которых обычно и определялась восьмерка с Казахстана. Тем не менее, использовать результаты Республиканского этапа кажется разумным методом. Несмотря на кардинальное различия в форматах, обе олимпиады сложные, из чего следует, что участник, хорошо выступивший на респе, скорее всего достойно покажет себя на Менделеевской. В данном посте, мы попытаемся ответить на несколько вопросов опираясь на здравый смысл и самое важное на данные:
- Есть ли вообще взаимосвязь между выступлением на Менделеевской(Мендель) и на Республиканской(Респа)?
- Есть ли она есть, то какая? Насколько уверенно мы можем полагаться на эту связь?
- Есть ли различие между выступлением 10 и 11-х классов? Снова, если оно есть, то какое?
Disclaimer
Данный пост опирается на линейную регрессию(Simple Linear Regression), самый простой метод статистического анализа. Мы не будем пытаться вывести “точную” формулу отбора на Мендель, так как это просто невозможно! Безмерное количество факторов может повлиять на выступление школьников. Начиная от их подготовки и заканчивая их настроением и самочувствием. О последнем мы разумеется можем только гадать, и никаких данных об этом не может быть.
Результаты
Хорошо, теперь можно начинать. Сначала, нам нужна хоть какая-то информация. Начнем с Scorebord, где есть результаты Менделя и Респы за последние 6 лет, и соберем данные в таблицу. Все дальнейшие шаги с кодом показаны по этой ссылке, здесь же мы обсудим результат.
Во-первых, взглянем на график:
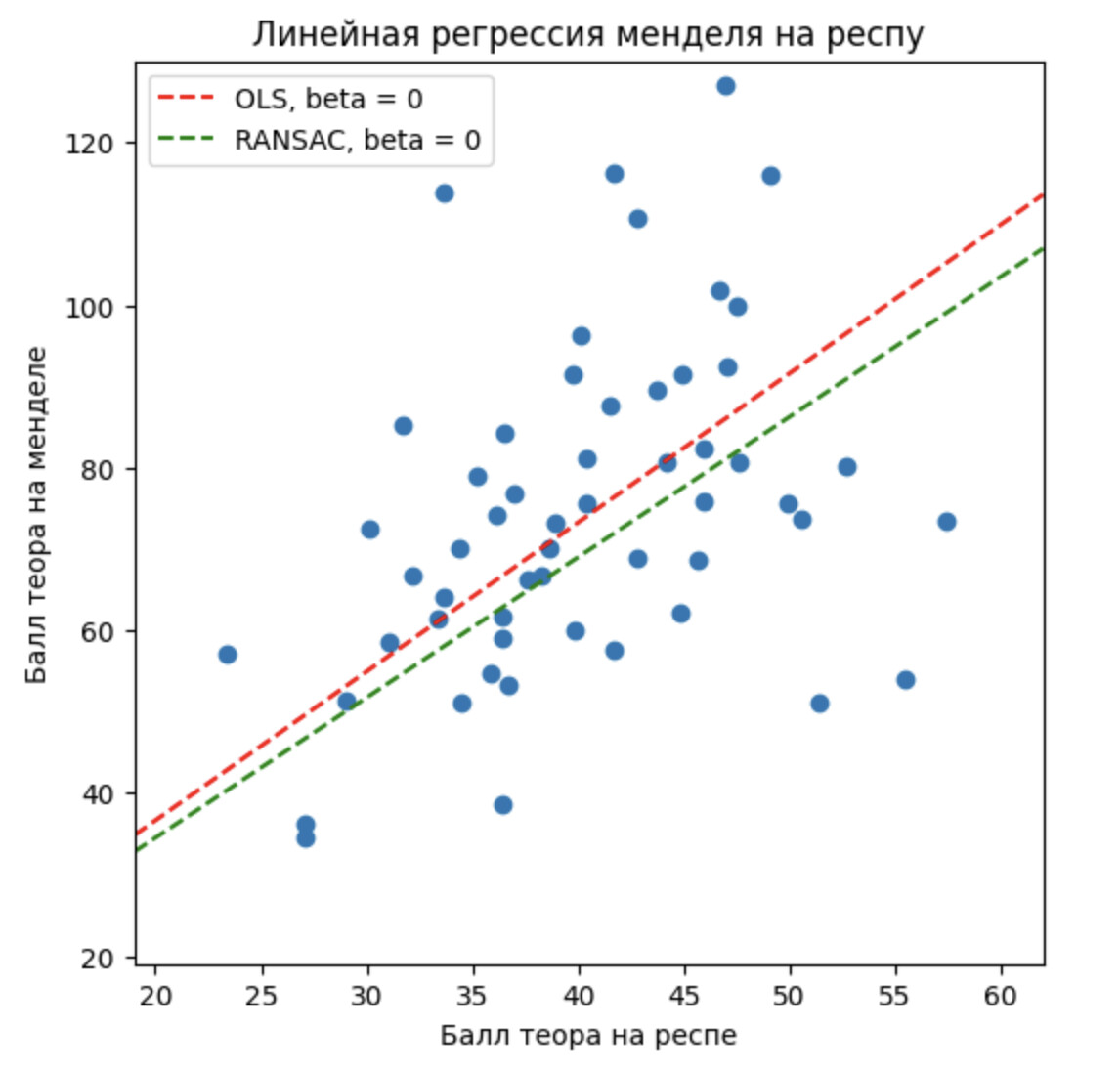
На мой взгляд, визуально the best fit line довольно хорошо проходится по данным. Конечно, мы видим, что много точек не проходят идеально по линии. Тут нужно остановиться и вспомнить, что результат на олимпиаде зависит от десятков факторов. И это удивительно, что результат на респе может иметь линейную зависимость(конечно в очень сильном приближении) от результата на Менделе. Как минимум, для бОльшего количество участников. Давайте, теперь с цифрами. В первом приближении результат Менделя (Y) зависит от балла на Респе (X) линейно:
Стандартное отклонение, \sigma = 0.064 для наклона. Для меня самым поразительным является то, что эта простая формула предсказывает результат 65% участников c погрешностью 10% или менее. В данном случае это 35 из 54 учеников! Если мы повысим порог допустимой ошибки в \pm 20%, то получается уже 44 из 54, что будет 81%. И визуально можно понять для кого это формула не работает.
- Первая группа - те, кто хорошо написали теоретический тур Менделеевской. А-ля 110 баллов или больше. Таких лишь 5 с 2018 года, можно даже из графика посчитать.
- Вторая группа - те, кто по каким-то другим обстоятельством написали Менделеевскую не так хорошо как могли.
Идем дальше. Если построить график предсказанного результата от cтандартизированной ошибки, то получим:
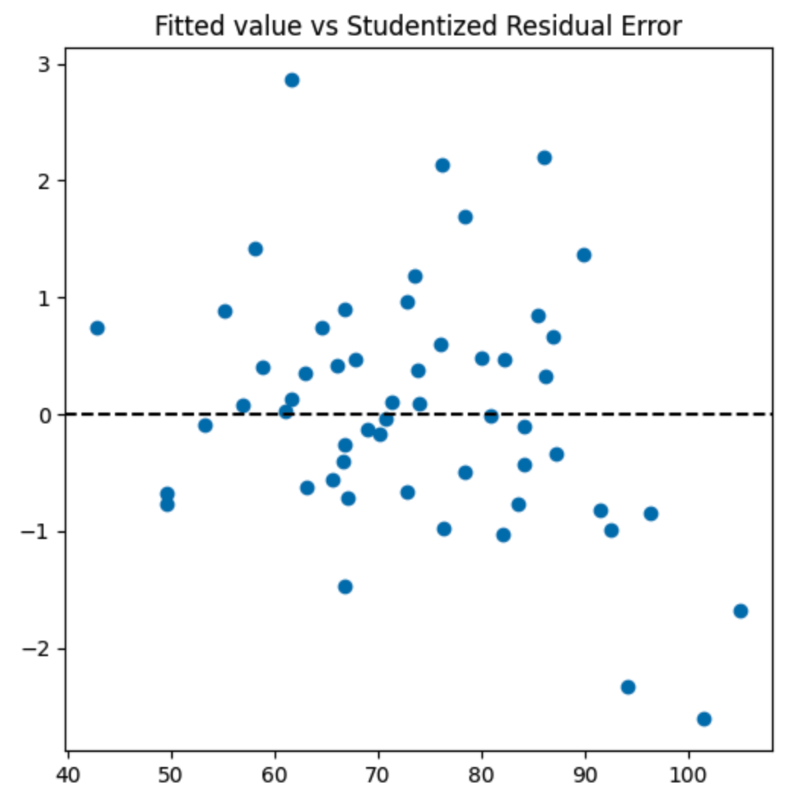
Проcтое правило - если нет значений больше 3 или меньше -3, то нет наблюдений сильно нарушающих линейную зависимость (Outlier). Один мой хороший друг, с которым я участвовал на этой Олимпиаде имеет значение 2.86, но он скорее исключение чем правило.
Другое интересное наблюдение следует из Ящика с усами (boxplot). Если сгруппировать участников на 10 и 11 классы и сравнить их результат, то мы получим:
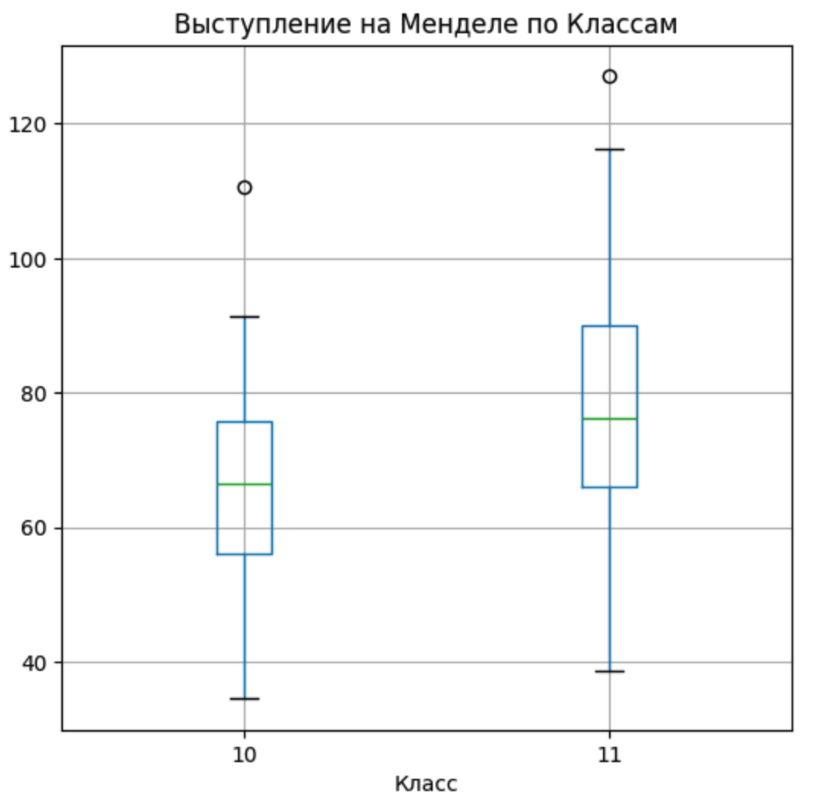
В принципе, ожидаемо, что 11 классники в среднем пишут лучше чем 10 классники. Конечно, есть исключения, но в среднем у 11-х выше медианное, верхний и нижний квартили.
Недостатки
Конечно, не все так радужно. Кто-то может спросить а какое значение R^2 линейного приближения. И я отвечу, что 0.15. Даже и неблизко к одному. Однако, не стоит забывать что вообще показывает R^2. Одна из интерпретаций - доля зависимости, которое объясняется регрессией. Грубо говоря, простая линейная зависимость от Респы может объяснить 15% результата участника на Менделе. В остальные 85% может входить как и ознакомленность с форматом Менделя, так и просто настрой участника. Слишком много переменных. Да и к тому же задачи Менделя и Респы разные каждый год, и использовать их для сравнения между друг другом не самый корректный способ. Например, набрать 50 баллов в 2022 намного сложнее чем в 2018 (мое скромное мнение). Скорее всего, можно улучшить эту формулу придумав относительные веса сложности для каждой респы. Но это довольно субъективная вещь, и как бы не начать просто подгонять.
Честно, самым ошеломительным результатом для меня была формула Y = X \cdot 1.832. Умножить только на константу. Это формула “работает” вопреки всем факторам.
Note
Если это читает школьник, который хочет достойно выступить на Менделеевской, но получил скажем 40 баллов на респе (что очень хорошо) и думает, что обречен на 73 балла по теории, то я спешу вас огорчить. Во-первых, формула является грубейшим приближением реальной жизни. Я повторил это уже несколько раз. Во-вторых, то как вы выступите на олимпиаде не что-то предопределенное. Вы решаете какой будет ваш балл на Менделе, и полно примеров людей, для которых это формула не работает даже и близко. Так будьте этим самим участником.